Набор большого объема текста может занять достаточно много времени, даже если это всего лишь автоматическая перепечатка информации, например, с картинки, когда имеется фото печатного текстового материала.
Поэтому достаточно часто возникает необходимость автоматизировать этот процесс.
В этом материале будет рассмотрено, как производится автоматическое распознавание печатного текста с картинки и конвертация его в печатный формат.
Суть процедуры
О каком же процессе в данном случае вообще идет речь? Обработка картинки или фото для того, чтобы текст, запечатленный на ней, автоматически был переведен в текстовый формат.
Тоесть, технически процесс происходит следующим образом: пользователь загружает картинку на сервер, либо переносит ее в программу, софт обрабатывает изображение, используя особые алгоритмы, и выдает в виде файла или в окне программы сфотографированный текст в печатном виде.
Они отличаются по функционалу совсем незначительно, но могут существенно отличаться по качеству обработки.
Некоторые программы допускают достаточно много ошибок в распознаваемом тексте, тогда как другие – распознают все практически идеально.
Качество распознавания зависит от изначального качества фото, но при прочих равных условиях большую роль играют алгоритмы работу и обширность базы используемого приложения или онлайн-сервиса.
 <Рис. 1 Особенности>
<Рис. 1 Особенности>
Принцип действия
Как же работает такая программа? Какие алгоритмы используются для распознавания текста и как они взаимодействуют в софте? Чем объясняются отличия в качестве распознавания материалов разными программами?
1 В каждой программе имеется база данных, в которую занесен алфавит, при этом каждой букве, как строчной, так и заглавной, присваивается целая группа вероятных графических отображений этой буквы – различные шрифты, учет качества фото, поворота и угла камеры при съемке и т. д.;
2 Таким образом, после попадания в программу изображение анализируется с целью выявления имеющихся символов и определения их положения, то есть, фактически, определяется, где именно на фото расположены буквы;
3 Распознавание обнаруженных букв, по окончанию которого формируется печатный текст;
4 Распознавание особенностей форматирования, величины отступов и т. д. (только некоторые программы способны сохранять форматирование, при работе большинства доступных бесплатных сервисов этот пункт вовсе отсутствует);
5 Как только распознавание заканчивается, то, в зависимости от типа программы и принципов ее работы, готовый текст появляется в окне софта или создается текстовый файл с ним (того или иного формата, также в зависимости от программы).
Полученный таким образом материал остается только отредактировать.
 <Рис. 2 Принцип>
<Рис. 2 Принцип>
Особенности
Каждая программа способна работать только с теми символами, которые были занесены в ее базу, только их она распознает.
В программу может быть внесено несколько алфавитов, как уже писалось выше, поэтому, при выборе подходящего софта проверьте, что бы он работал с языком, на котором напечатан текст на вашей картинке.
Если речь идет о не слишком популярных и визуально нестандартных языках, то найти подходящий софт может быть непросто.
Чем сложнее форматирование или расположение букв на фотографии, тем сложнее программе правильно распознать текст, и тем больше будет ошибок.
Ведь иногда в таком случае неточности могут возникнуть уже на стадии определения местоположения печатных символов на картинке.
При определении буквы программа использует определенный «алгоритм» сравнений с ее основными чертами – расположением и размером элементов (некоторые утилиты также учитывают соседние распознанные буквы и лексическую сочетаемость).
Благодаря этой особенности, даже если небольшая часть буквы стерлась или изменена, она все еще может быть распознана.
Перед началом процесса распознавания, обратите внимание на качество фото.
Лучше всего определяется текст с отсканированных изображений документов, скриншотов.
Хуже всего распознаются материалы с фото плохого качества, сделанного под углом, особенно если имеет место сложное форматирование.
Художественные шрифты не распознаются.
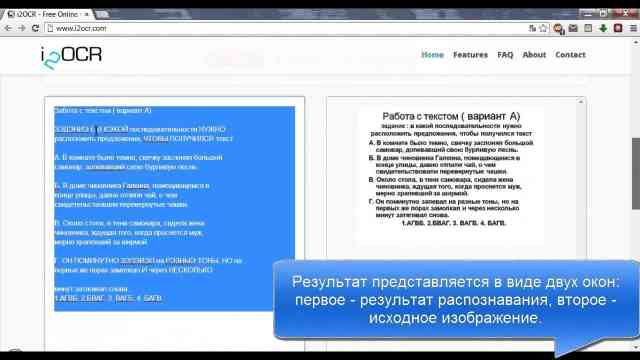 <Рис. 3 Онлайн-сервис>
<Рис. 3 Онлайн-сервис>
Преимущества и недостатки
Преимущества использования таких сервисов очевидны.
Основное из них – это существенная экономия времени на обработку материала.
И хотя текст, получаемый на выходе, может иметь даже очень низкое качество, редактирование его все равно займет, в большинстве случаев, меньше времени, нежели перепечатка «с нуля».
- Значительная экономия времени, уходящего на автоматическую перепечатку текста;
- Избежание ошибок в формулах и сложных символьных построениях, которые могут быть при ручной перепечатке материала (справедливо только в случае, если используется качественный софт, способный достоверно распознавать сложные символьные комбинации);
- Распознавание и перенесение текста, который вы не можете напечатать на своей клавиатуре (например, текст с арабской вязью, иероглифами и другими символами, которые отсутствуют на традиционной русско-английской клавиатуры).
- Хотя, строго говоря, преимуществ в использовании таких программ достаточно мало, они завоевывают все новых и новых поклонников, так как помогают экономить время (или создают иллюзию экономии, так как фактически на редактуру некачественно обработанного софтом текста уходит времени больше, чем на его изначальную перепечатку).
- Ограниченность базы языков – то есть, определенная программа рассчитана на распознавание определенных символов, и часто, это могут быть символы только какого-нибудь одного языка. В других программах в базу может быть занесено несколько алфавитов, но, обычно, такой софт ограничивается 1-3 языками;
- Большие сложности бывают при работе с текстом смещенного типа, то есть таким, который содержит как русские, так и английские символы. Вы можете выбрать только один язык текста и алфавит для распознавания, что ведет к тому, что все, напечатанное другим алфавитом распознаваться не будет. В зависимости от типа, сложности и качества софта эта проблема может быть выражена в большей или меньшей степени;
- Потеря форматирования либо неспособность распознать особенности изначального оформления текста – выходной файл часто представляет собой почти файл Блокнота по оформлению;
- Просто низкое качество распознавания, связанное с неверной настройкой или некачественной проработкой самого софта, когда буквы распознаются ошибочно;
- Ошибки распознавания, связанные с изначальным низким качеством фото. Не любой софт работает с фото плохого качества и тщательно его обрабатывает;
- Серьезные проблемы с распознаванием возникают в случаях, когда текст расположен блоками, распределенными по фото неравномерно или даже в две колонки – лучше всего этот софт распознает сплошной текст;
- Качество распознавания может падать по мере добавления все новых и новых фото за один сеанс;
- Иногда процесс обработки изображения может идти очень долго, так как его скорость падает по мере увеличения длительности нагрузки на программу;
- Стандартное для почти всех программ, очень низкое качество распознавания «сложных» алфавитов, например, иероглифов или арабской вязи. Ошибки, причем достаточно крупные, в этом случае неизбежны;
- Неверное распознавание символьных групп – ситуация, при которой две, расположенные рядом, буквы ошибочно распознаются программой как одна. Причем, при возникновении такой ошибки могут смешиваться символы различных алфавитов, и изначальное корректное сочетание иногда бывает сложно угадать. Встречается такая ошибка очень часто.
 <Рис. 4 Методы>
<Рис. 4 Методы>
Сфера применения
Какие же группы пользователей работают с таким софтом, и для кого он будет удобен?
Также софт пригодится при составлении документа или нормативного акта по образцу, который уже имеется в напечатанном виде и т. п.
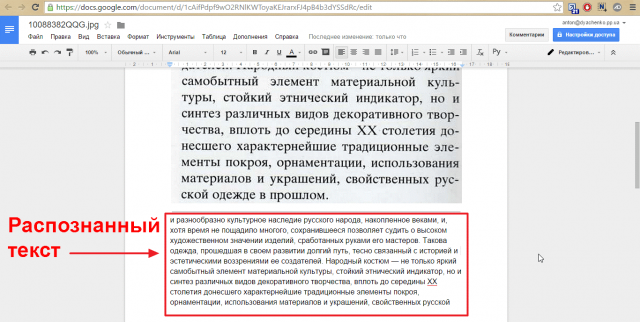 <Рис. 5 Результат>
<Рис. 5 Результат>
Функционал
Функционал у данных программ достаточно стандартный – он позволяет произвести загрузку фото, выбор языка, запуск обработки и получение готового текста.
В некоторых утилитах текст отображается в окне, в других – оформляется в файл указанного или установленного по умолчанию формата, иногда файл также может быть создан по запросу.
В некоторых платных приложениях могут быть реализованы и другие функции, например, улучшение качества фото с целью увеличения распознаваемости текста.
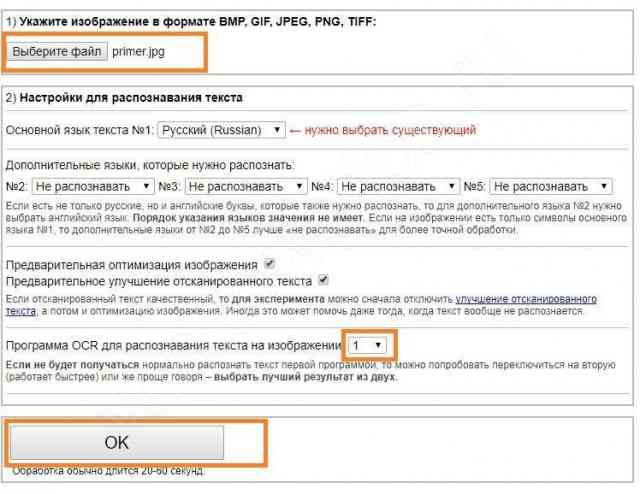 <Рис. 6 Функционал онлайн-сервиса>
<Рис. 6 Функционал онлайн-сервиса>
Программы
Какие же программы используются для распознавания?
Они делятся на две группы: платные и бесплатные установочные программы, платные и бесплатные мобильные утилиты.
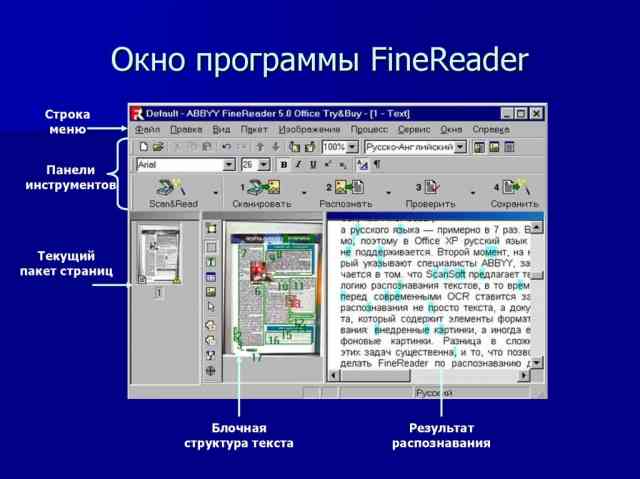 <Рис. 7 FineReader>
<Рис. 7 FineReader>
Требующие установки
Такой софт подойдет тем, кто постоянно работает с изображениями с текстом.
Кроме того, такой софт, обычно, наиболее функциональный.
| Программа | Тип лицензии | Функционал | Особенности | Рейтинг |
|---|---|---|---|---|
| ABBYY FineReader | Платно | Полный | Подходит для профессионального распознавания текста | 4,0 |
| CuneiForm | Бесплатно | Суженный | Неплохой функционал, но меньший, чем в платных аналогах | 2,9 |
| ABBYY PDF Transformer | Платно | Расширенный | Программа предназначена для выполнения широкого спектра работ с файлами PDF, в том числе и с распознаванием текста со сканов | 3,4 |
| Readiris Pro | Платно | Более узкий, по сравнению с другими платными аналогами | Довольно неудобное меню и управление, из-за которого программа не пользуется популярностью | 3,0 |
Не требующие установки
Качественных мобильных утилит достаточно мало.
Они нужны тем, кто часто работает за разными компьютерами для того, чтобы не устанавливать программу на каждый.
Наиболее популярным таким софтом является утилита VueScan.
 <Рис. 8 CuneiForm>
<Рис. 8 CuneiForm>
Она распространяется бесплатна и способна обрабатывать изображения с текстом, полученные со сканеров.
Обладает достаточно широким функционалом, не ограничивающимся только распознаванием текста.
